













Ensuring data protection is a top priority for businesses of all sizes, both in terms of safeguarding information and complying with regulatory standards. Data protection in the cloud is fundamentally pivotal as organisations entrust their sensitive data to third-party providers. In this blog post, we will discuss the importance of using best practices for data protection and how AWS and Liquid C2 are committed to protecting customer data while offering a list of comprehensive sets of features and services to help businesses protect their data in the cloud.
Today, we will cover the below topics in detail:
- The AWS Shared Responsibility Model, and how businesses can work with AWS to ensure the security of their data.
- The importance of creating a data classification framework for your data.
- S3 best practices to ensure data protection.
- Utilising Macie to help automate detection of sensitive data.
- EC2 best practices to ensure data protection.
AWS Shared Responsibility Model
The AWS Shared Responsibility Model is a framework that allocates cloud operations responsibilities, including security, between AWS and its customers. In general, AWS is responsible for the security of the cloud, its global infrastructure, including data centres, networking, and hardware. AWS manages the security and maintenance of the hardware and software that run its services. Customers are responsible for security in the cloud, securing their own data, including encryption, access control, and compliance with regulations. Customers must manage user access to AWS resources, using Identity and Access Management (IAM) tools to control who can do what. Security within the customer’s operating system, applications, and data is their responsibility.
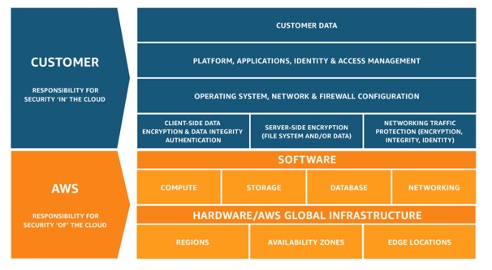
AWS Shared Responsibility Model
However, it is important to note that not all AWS products have the same responsibility model. Some products like Lambda and S3 are considered managed solutions, where AWS is responsible for the majority of the stack. On the other hand, some products like EC2 give their customers more freedom and customisation, but at the cost of more responsibility on part of the customer.
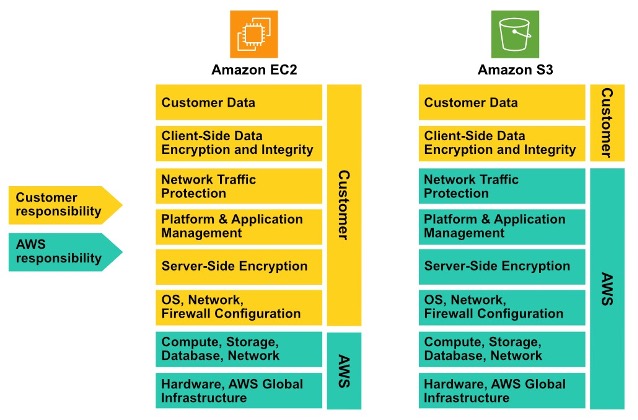
Overview of the Shared Responsibility Framework for both EC2 and S3
An understanding of the shared responsibility model and its nuances enables AWS customers to make the right choice in selecting AWS products to fulfil their technology and operational requirements.
Data Classification Framework
A data classification framework involves categorising and labelling your data based on its sensitivity, regulatory requirements, and business value. AWS provides various tools and services that can be utilised to build and enforce a data classification framework.
To protect your data, you first need to understand how it’s classified. What type of data do you have? Is it Intellectual Property (IP), such as trade secrets or contract agreements? Is it Personally Identifiable Information (PII) data, such as health records or credit card numbers? Each type of data needs to be protected differently, depending on its sensitivity and the regulations that apply on it.
For example, hospitals and clinics that operate in the United States need to follow HIPAA, which is a set of regulations governing the privacy and security of health information. Similarly, if you serve customers from Europe, you need to follow GDPR, which is a set of regulations governing the protection of personal data. For more information on AWS security and compliance reports, visit https://aws.amazon.com/artifact/
In the AWS cloud environment, data classification can be done in four simple steps:
- Design your data classification framework. This involves creating a set of data classification labels, such as Official, Secret, and Top Secret. The labels should be based on the data’s sensitivity and value, as well as any applicable regulations.
- Tag your data. You can use resource tags to categorise your resources and apply the classification framework you created. For example, you can tag a Lambda function that is processing credit cards data as “Secret”, or “Top Secret, which in turn allows you to restrict access to this function to authorized users only.
- Automate actions using resource tags. Resource tags can also be used to trigger automated actions, such as running another Lambda function to mask the credit card data before storing it in a database.
- Redact sensitive data. Sensitive data, such as credit card numbers and social security numbers, should be redacted before it is stored in the cloud. This can be done using a variety of tools and techniques.
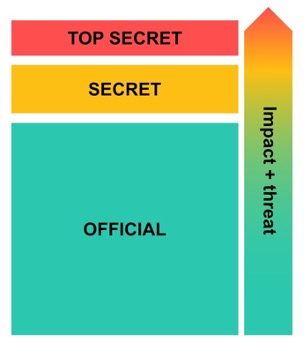
Three-tiered data classification framework
- Keep up with compliance. Make sure that your data classification and protection practices are compliant with all applicable regulations. This may involve storing certain types of data in specific regions or using specific encryption methods. Additionally, you would need to implement procedures for continuous monitoring of data being stored or transmitted, to ensure that your business stays compliant.
Data classification is a broad topic and different corporate or government environments require different implementations, so we suggest that you would have a look at this data classification whitepaper which would provide you with more nuisances regarding data classifications.
With both the shared responsibility model and data classification in mind, we can start to explore three crucial AWS services that businesses should contemplate when transitioning their infrastructure to the cloud.
AWS Simple Storage Service – S3
Amazon S3 is a highly scalable and secure object storage service provided by AWS. It allows users to store and retrieve any amount of data at any time from the internet. Here are some of the key features and aspects of Amazon S3:
- Object Storage: Data is stored in the form of objects. An object consists of data, a unique key (or identifier), and metadata. Objects can include anything from text files and images to videos and application backups.
- Scalability: Amazon S3 is highly scalable, allowing you to store and retrieve virtually any amount of data. It automatically scales to handle growing workloads and can accommodate large amounts of data.
- Durability and Reliability: S3 is designed for durability and reliability. It stores data across multiple facilities and servers, ensuring high availability and durability. Amazon S3 Standard provides 99.999999999% (11 nines) durability of objects over a given year.
- Metadata: S3 allows you to attach metadata tags to objects for categorisation, organisation, and retrieval. This metadata can be used to filter and search your data, enabling efficient management and retrieval.
- Monitoring: S3 provides monitoring and alerting capabilities to track storage usage, access patterns, and performance metrics. This helps you identify and troubleshoot potential issues with your S3 storage.
While S3 is a managed product, which means a chunk of the responsibility falls on AWS, it is up to the customer to make sure it is configured correctly and securely.
Here are some important configurations and best practices you should consider when using S3:
- Keeping the bucket off the internet. If it is a private bucket with sensitive data that should not be on the internet, Amazon S3 provides settings to block public access. This setting can be applied to individual buckets or to all the buckets in your account.
- Grant access to specific people. Bucket (resource) policies are applied on buckets themselves, and they grant or deny access to users trying to access this bucket.
- Encryption. To make sure objects are encrypted on a bucket, there are several types of encryption you can allow, which will require every object written on the bucket to be encrypted.
- Client Side Encryption: The data is encrypted before it enters the encrypted TLS tunnel going to the S3 bucket and stays that way, and, until it is at rest, S3 cannot see it. You own and control the keys and the process. This is encrypting data in transit.
- Server Side Encryption: The data is encrypted before it gets stored in S3. This is encrypting data at rest. There are several options available to implement this:
- SSE-C: Server-Side Encryption with customer-provided keys.
- SSE-S3: Server-Side Encryption with Amazon S3-Managed Keys.
- SSE-KMS: Server-Side Encryption with Customer Master Keys (CMKs) Stored in AWS KMS.
- Object Versioning. This is used to keep multiple variants of an object in the same bucket. It is disabled by default, and once enabled, can only be suspended, but not disabled. It can be used to make sure no data is ever actually deleted, and all versions of the files are stored indefinitely.
- MFA Delete. Alongside versioning, another optional layer of security is MFA Delete, which forces the bucket owner to include two forms of authentication with any request deleting a version or changing a version state of the bucket. This feature can only be enabled using AWS CLI or the API.
- Pre-signed URLs. This is S3’s way to allow object owners to give unauthenticated users access to specific objects. Pre-signed URLs provide access using the same IAM role that created the URL and can be used to grant access to objects in a private S3 bucket. They are time-limited, and encode all the authentication information inside the URL. Pre-signed URLs can be used for downloads (GET operations) and uploads (PUT operations).
Amazon Macie
Amazon Macie is a managed security service that uses machine learning to automatically discover, classify, and protect sensitive data. It utilises machine learning and pattern matching to detect pre-sets and custom matches for known sensitive data. Amazon Macie can scan S3 buckets for things such as names, addresses, credit card numbers, PII (Personally Identifiable Information), PHI (Protected Health Information) and more, while continually monitoring configurations for encryption, access policies and other best practices. Currently, Amazon Macie only supports S3, but future iterations might support other storage types as well.
To configure some identifiers, you can either use:
- Managed Data Identifiers. These are built-in and have machine learning and pattern analysis capabilities that capture most of the frequent important information.
- Custom Data Identifiers. These are regex-based identifiers that are customised to fit the specific data that you are storing on S3.
You use Macie, you create a Discovery Job, which is a series of automated processing and analysis tasks that Macie performs, add the data identifiers to it and it will automatically start searching and discovering them. You can then integrate this with other Amazon services to pass the data to AWS Security Hub or AWS EventBridge for automatic remediation of discovered findings.
AWS Elastic Compute Cloud – EC2
Amazon Elastic Compute Cloud (EC2) is one of the core services offering scalable compute capacity in the cloud. It allows users to run virtual servers, known as instances, on demand. You can use EC2 to launch as many or as few VMs as you require, configure them with the latest operating systems and software, and manage them using AWS Management Console, AWS Command Line Interface, or AWS SDKs.
Although EC2 is a managed service, it offers great flexibility to its customers. For example, you can choose to get a dedicated host or a dedicated instance from Amazon; which could be a requirement if your business needs to follow strict regulatory and security requirements that prohibit your organization’s data from being physically stored on shared hardware.
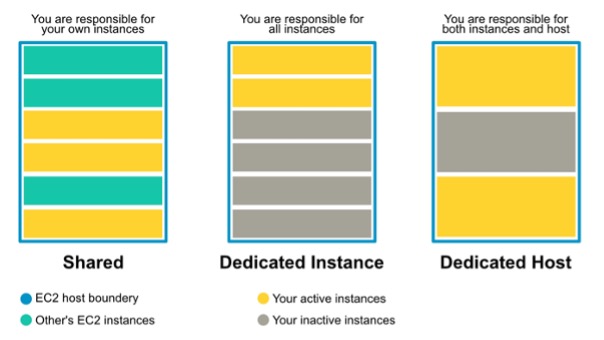
Differences between some EC2 configuration types
Here are some important configurations and best practices you should consider when using EC2:
- Create IAM roles to manage access to EC2 instances. IAM roles can be used to grant temporary credentials to users, groups, or applications. These temporary credentials can then be assumed by entities which you deem to be trusted to gain temporary access to your AWS resources.
For example, you could create an IAM role that only allows read-only access to EC2 instances. This would prevent trusted entities who assume that role from making changes to the instances, which could help protect your data and applications.
You can also create more granular IAM roles, such as ones that allow trusted entities to start and stop EC2 instances, but not to modify them. This gives you more control over how your EC2 instances are used.
- Create EBS snapshots to prevent data loss. EBS volumes are stored in a single Availability Zone (AZ) in AWS. If that AZ goes down, your data could be lost. EBS provides the ability to create snapshots (backups) storing copies of that data in S3 redundantly across multiple AZs. This means that your snapshots will be replicated across multiple AZs, so you can restore your data even if an AZ goes down. Moreover, you can encrypt your EBS snapshots, which would help protect your data from unauthorized access.
- Amazon EBS encryption. This is a simple and secure way to encrypt your EBS resources associated with your EC2 instances. It eliminates the need to build, maintain, and secure your own key management infrastructure. Amazon EBS encryption uses AWS KMS keys to encrypt your volumes and snapshots.
Encryption operations occur on the servers that host EC2 instances, ensuring that your data is secure at rest and in transit. You can attach both encrypted and unencrypted volumes to an instance simultaneously.
- Enable instance metadata protection. Instance metadata is data about your instance that you can use to configure or manage the running instance. Instance metadata is divided into categories, which include host name, events, and security groups. Note that instance metadata can be accessed by anyone or any software on the instance itself, thus it is recommended not to store sensitive data, such as passwords or encryption keys on it.
There are two main ways to protect instance metadata in AWS EC2:
- IMDSv2 (Instance Metadata Service Version 2): Which is a more secure version of the IMDSv1 that requires authentication when transferring the data between the instance and the IMDS. At the time or writing, IMDSv2 is the default version of the IMDS, and it is recommended that you use it for all new instances.
- Instance metadata options: The instance metadata options allow you to control who can access the instance metadata. You can configure the instance metadata options to allow only specific users or groups to access the metadata.
- Utilize Amazon Inspector. Amazon Inspector is an automated vulnerability management service that helps you identify and remediate security vulnerabilities in your EC2 instances and other AWS services as well.
Amazon Inspector can scan your EC2 instances for vulnerabilities in the operating system, programming languages, and application packages that are installed on them. It can also scan your EC2 instances for network reachability issues.
Moreover, Amazon Inspector can be integrated with AWS Security Hub and to help you automate remediation of certain vulnerabilities found on your EC2 instances. For example, you can create an automation rule in Security Hub to applying patches or installing security updates on your EC2 instance.
Conclusion
In conclusion, data protection becomes critical for businesses, irrespective of their size. This concern is further magnified when data is entrusted to cloud service providers.
With the shift to the cloud becoming more prevalent, as it comes with a plethora of benefits, it does not come without its own set of risks, such as data protection. Understanding the necessary configurations required and the available services that complement security best practices is crucial. Liquid C2’s professional and managed services also provide clients with a unique opportunity to outsource the cloud operations and ongoing management by leveraging Liquid C2’s in-house team of experts, while such clients focus on their core business.
By adhering to the shared responsibility model, businesses can collaborate with AWS and Liquid C2 to fortify the security of their data in the cloud. Additionally, practices such as data classification, the implementation of S3 and EC2 best practices, and the utilization of tools like Amazon Macie for automated detection of sensitive data underscore the comprehensive approach AWS takes to data protection. Embracing these principles not only ensures the integrity and confidentiality of data but also empowers businesses to thrive securely in the digital age.
References
- Data protection – Security Pillar
- Data protection – Applying Security Practices to a Network Workload on AWS for Communications Service Providers
- Data classification whitepaper
- Automated Data Discovery for Amazon Macie | AWS News Blog
- How to use Amazon Macie to reduce the cost of discovering sensitive data | AWS Security Blog
- Best Practices for Tagging AWS Resources – Best Practices for Tagging AWS Resources
- Services that support the Resource Groups Tagging API – Resource Groups Tagging API
- What is Amazon S3?
- Amazon EC2
- AWS Lambda
- Tag your Amazon EC2 resources
- Regions and Zones
- What is AWS Security Hub?
- Amazon EventBridge
- Amazon EBS volumes
- Instance metadata categories
- Configure the instance metadata options
- Amazon Inspector
Authors
Omar Younis – Senior Red Team Consultant
Hello, I’m Omar Younis, Senior Red Team Consultant at Liquid C2. I’ve been in the Information Security field for over 6+ years with a focus on the offensive side of things. With a recent curiosity on the cloud realm, followed by an instant delve into several AWS courses and certifications.
When I’m not securing things, I’m either cooking, travelling or laying flat on my back.
Hosam Gemei – Senior Red Team Consultant
Hey, I’m Hosam Gemei, a Senior Red Team Consultant with 5+ years in cybersecurity and a software development background. I specialize in application and network penetration testing, with a passion for all things cyber and programming. When not safeguarding systems, I’m into reading, jogging, and gaming.